在学习Beautiful Soup4之前,我们先了解一下什么是Beautiful Soup。
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。
如上解释来自于官网,我用大家好理解的解释来说,就是一个Python库,用来解析HTML或XML文档内容的工具。我们之所以学习Beautiful Soup,原因是我们在写网络爬虫时,对于爬取的数据要进行解析,进行数据清洗,从而获得对于我们来说有效的数据。接下来以 Python3、beautifulsoup4 为基础版本,讲解从安装到使用逐一讲解。
一、安装
在正确安装了Python3后,只要在shell或命令行中安装beautifulsoup4与lxml即可,命令如下:
pip install beautifulsoup4 pip install lxml
二、使用步骤
在使用Beautiful Soup4需要分两步来走:
(1)创建bs4 对象,示例:bs = BeautifulSoup(网页内容变量, ‘lxml’);
(2)通过bs4中的 find_all() 或 find() 方法来查找内容。
三、简单应用
接下来展示一下bs4常用的三种解析内容的方式。
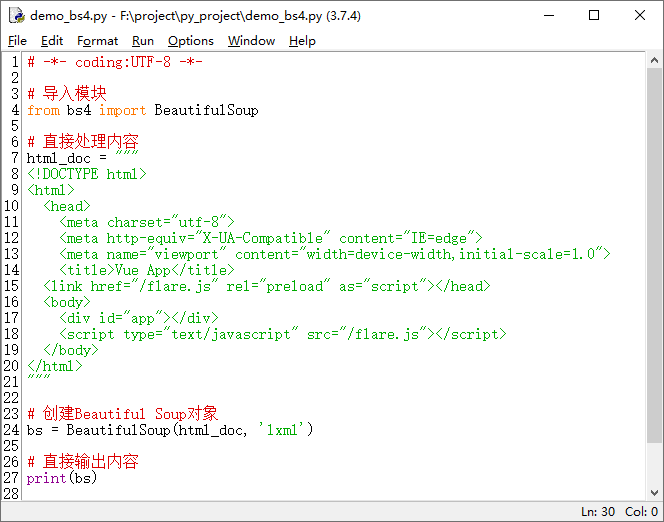
3.1 直接处理内容
这种方法呢,是直接处理HTML的代码,以字符的形式存储在一个变量中,以后就可以对其进行操作了。
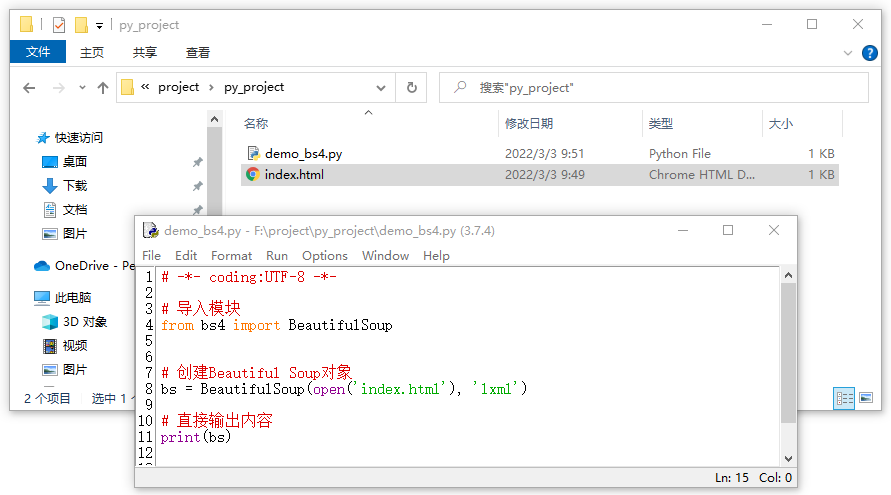
3.2 读取本地文件内容
这种方法呢,可以直接处理本地下已经存在HTML文档。我们使用 open() 方法来打开文件“index.html”,并将内容传给bs4处理。
3.3 在线读取网络上内容
这种方法呢,直接通过域名来获得网站上的HTML内容信息,这个也是最常用的一种方式。但需要通过 requests 模块才行。

四、格式化输出
对于bs4,在正常输出时,会把所有内容左对齐输出,这样降低了内容可读性,但好在bs4提供了格式化输出的方法。
未使用格式化输出示例图如下:
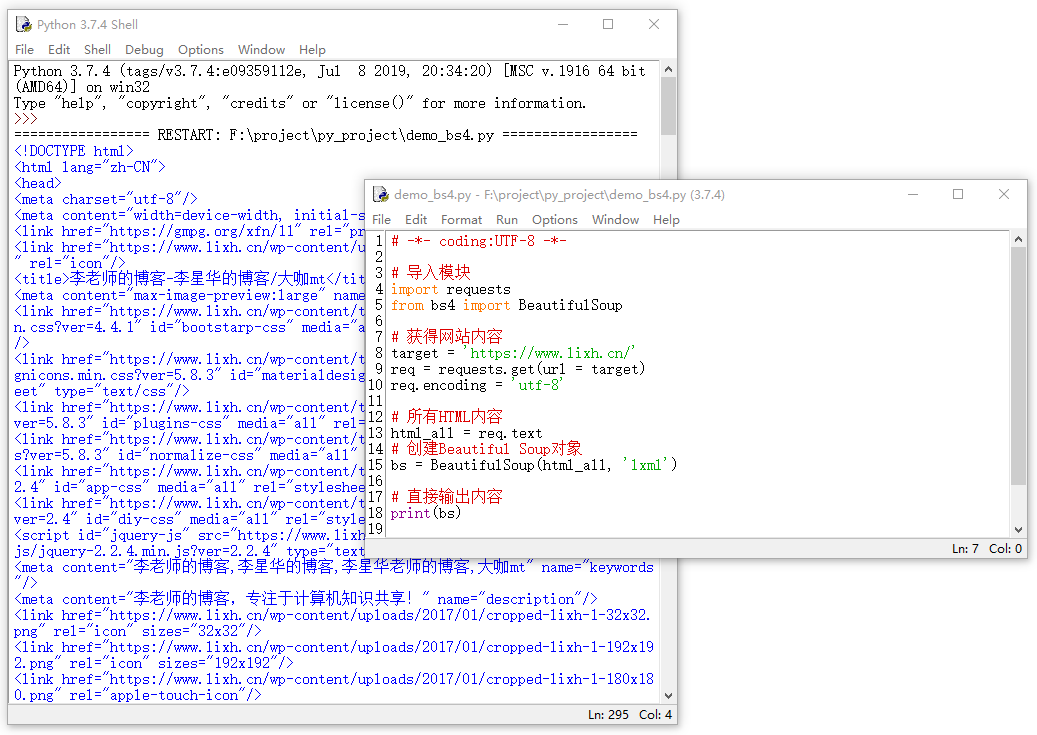
使用格式化输出示例图如下:
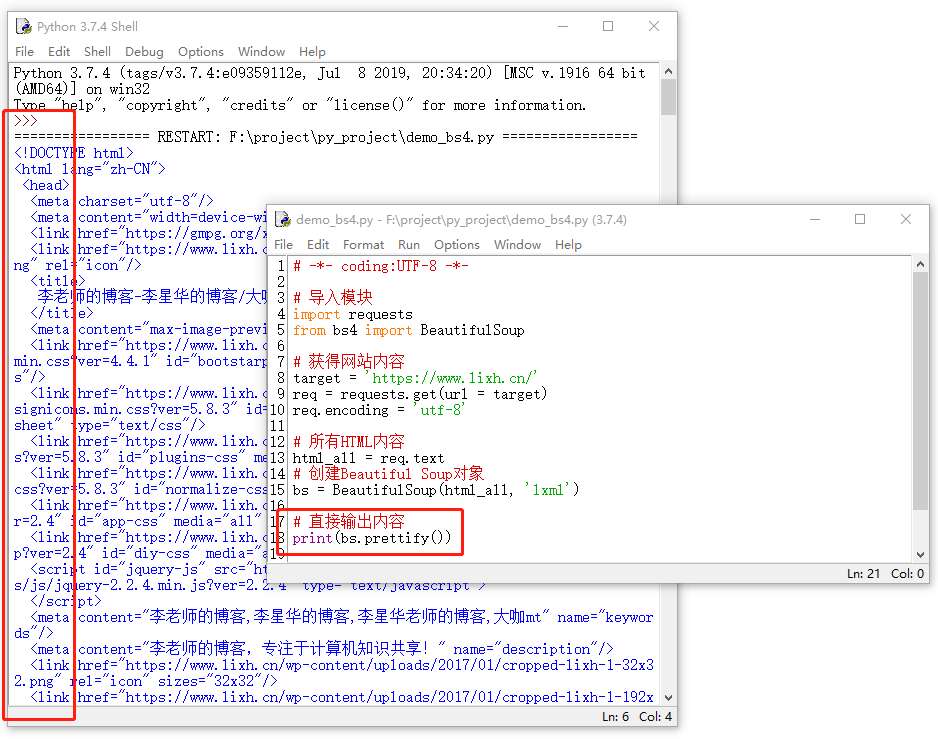
五、结构化标签的浏览
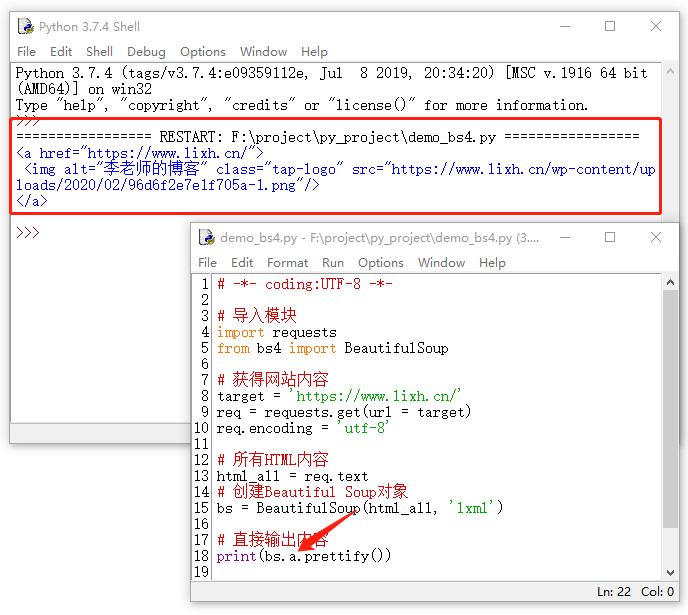
bs4提供了html标签的快速浏览功能,我们只需要将标签名称写出来即可。接下来我们以html中的body标签为例,展示图如下:

上面的只是一个示例,除了body之外,还可以是html、head、div、a等等,只要HTML中有的标签都可以使用。但话又说回来了,对于HTML中唯一的标签还好办,如果有不唯一的标签怎么办?在bs4中,如果标签不唯一,它只显示第一个符合条件的内容。
还有一个更好玩的地方,就是bs4可以实现层次级的标签处理,比如说在body -> div -> header -> div -> h2 这是用来描述层级关系的,如果这个层次关系有效,我们就能得到相应的结果。

细心的小伙伴有没有发现我用的是:
print(bs.body.div.header.div.h2.prettify())
而不是:
print(bs.body.div.header.div.div.h2.prettify())
这里面多了一个div,而且是网页的正常层次,而我省略了一个div,这里告诉大家,bs4很智能的,因为在div的下一层,不管有多少层级,我只找里面包含h2标签的内容,所以就节省了一个div。
那如果我只想取标签里的内容怎么办,只要在输出的内容上加个text就可以拉。
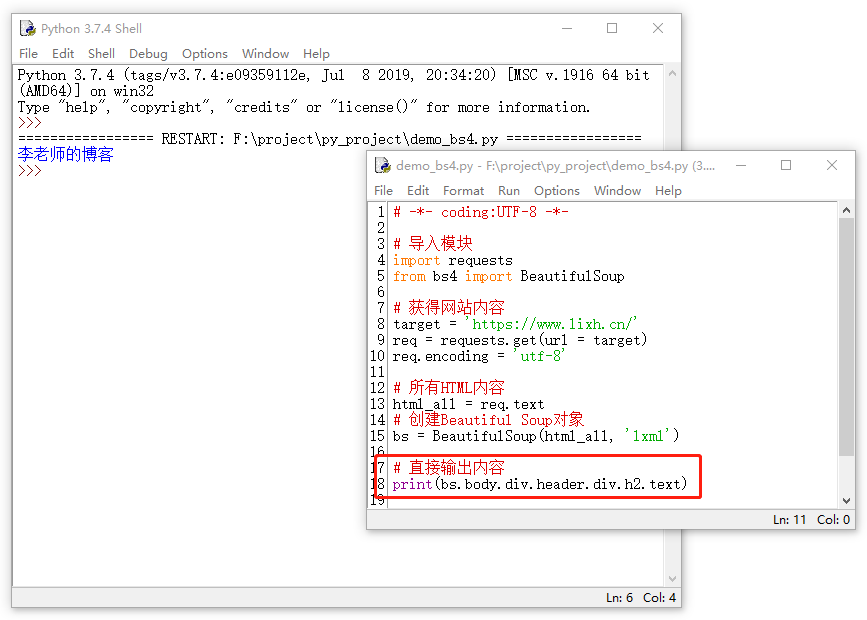
六、四种对象种类
在bs4中,将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag(标签)、 NavigableString(可遍历字符串) 、BeautifulSoup(bs对象)、Comment(注释内容)。
6.1 Tag标签
在bs4中标签的概念与HTML中的标签是一样的,即在HTML中成对出现的那些,如:<head></head>、<p></p>、<body></body>等等。对于bs4中的Tag,有两个重要的属性,name和attributes。
6.1.1 name
每个Tag都会有一个name,我们可以通过它获得标签的名称,也可以通过它来修改标签的名称,示例如下所示:
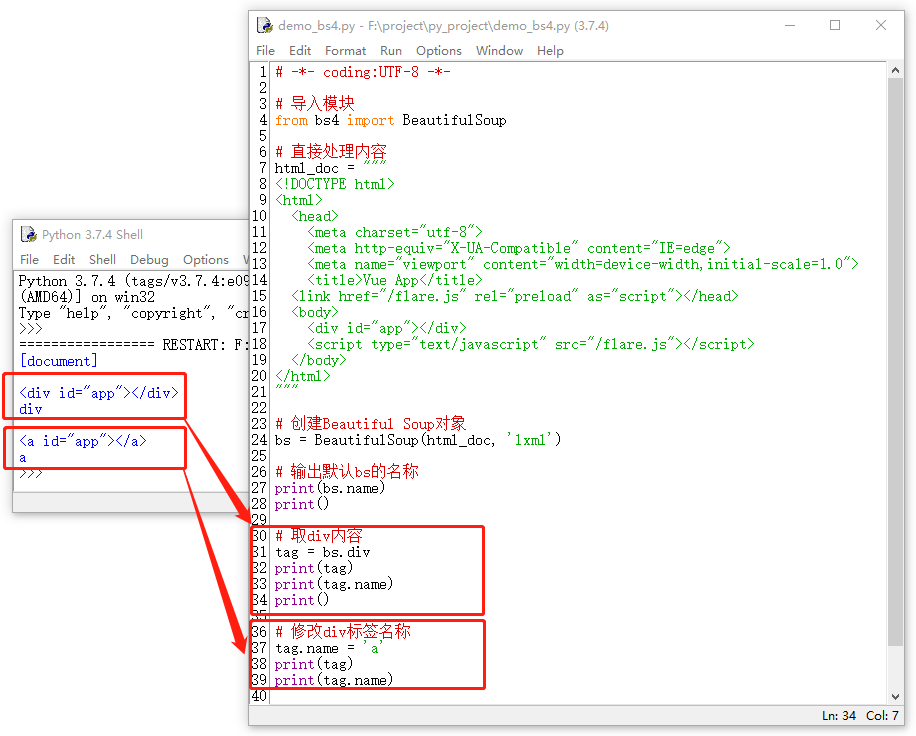
同时需要注意的是bs4默认的名称为“[document]”,在上图中已经证实。
6.1.2 attributes
每个Tag可以有一个或多个attributes,我们可以通过它来控制html标签中属性的内容,示例如下所示:
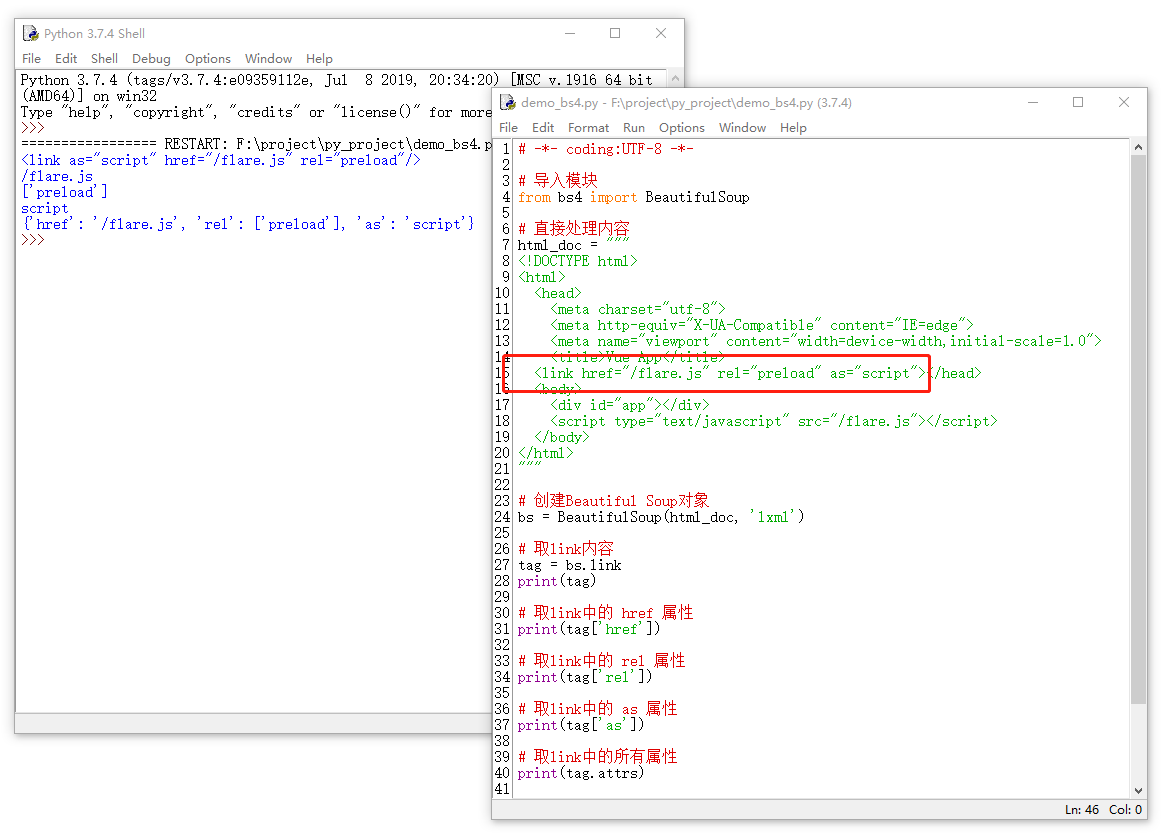
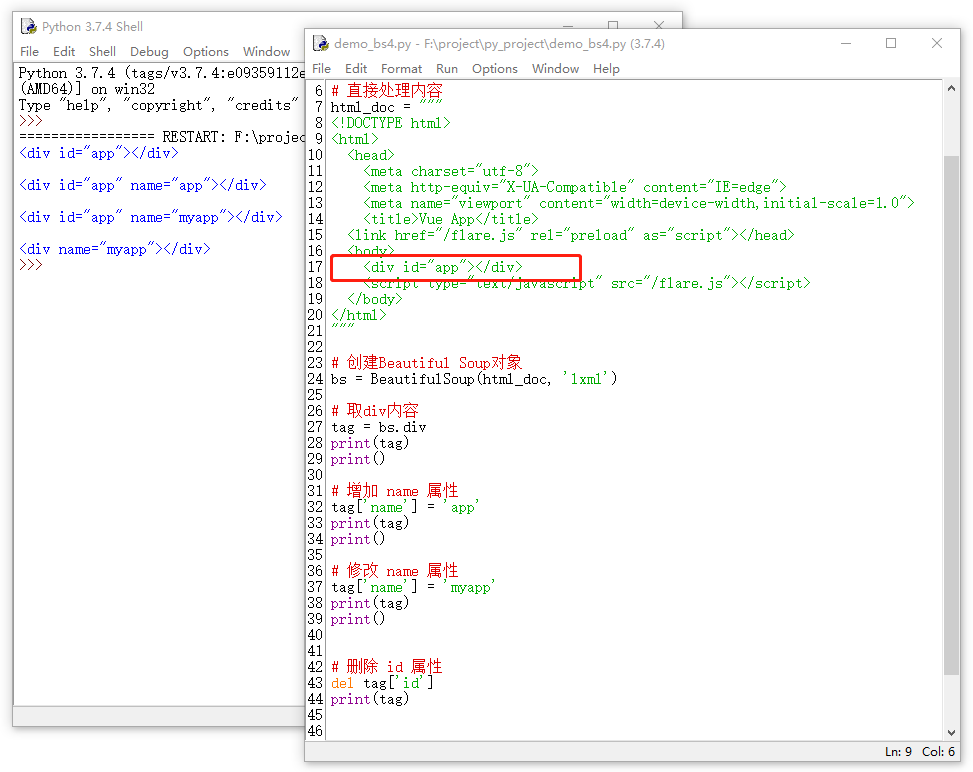
当然呢,我们可以像字典一下来操作attributes,可以其实基本的增加、删除和修改操作。
6.2 NavigableString(可遍历字符串)
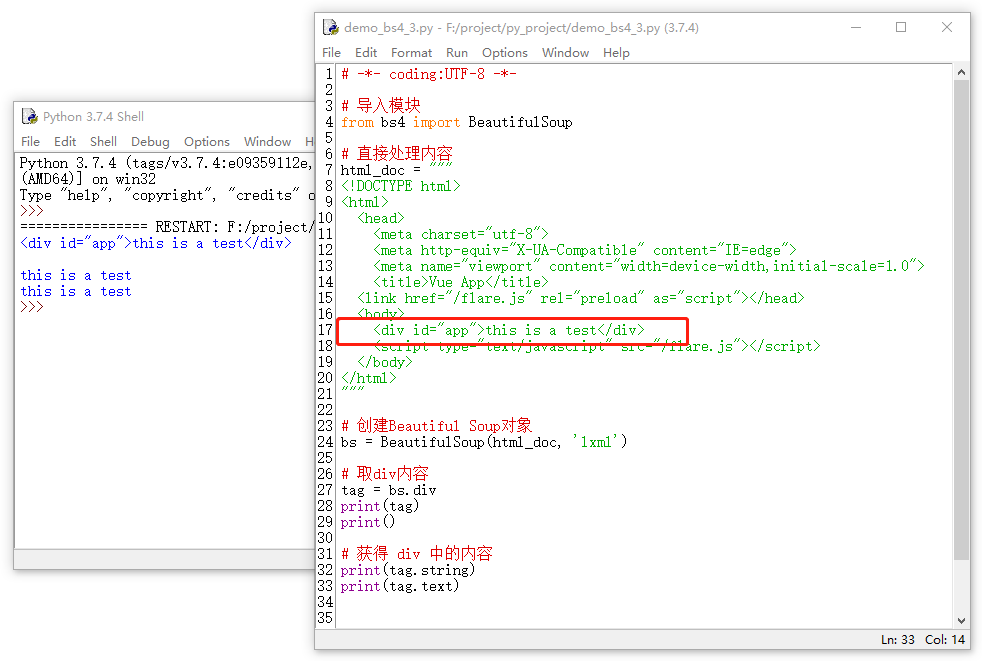
在bs4中,字符串是包含在html的标签内的,我们可以通过”.string”的方法来获得,当然也可以“.text”方法来获得。
6.3 BeautifulSoup(BS对象)
在bs4中,我们在使用之前,都会定义其对象,如:
bs = BeautifulSoup(html_doc, 'lxml')
这个对象呢,用来表示文档的全部内容,我们可以把它看作是一个特殊的Tag标签,因为这个特殊的Tag标签是没有name和attribute属性的。

6.4 Comment (注释)
在上面介绍的Tag(标签)、 NavigableString(可遍历字符串) 以及BeautifulSoup(bs对象)基本上将HTML操作控制点了大部分,还有一个可能出现在HTML文档中的就是注释。有时我们在编写网络爬虫时,需要将这些注释进行过滤,所以也要掌握其处理方法。我们在日常操作过程中,通常使用类型判断即可实现,示例如下所示:
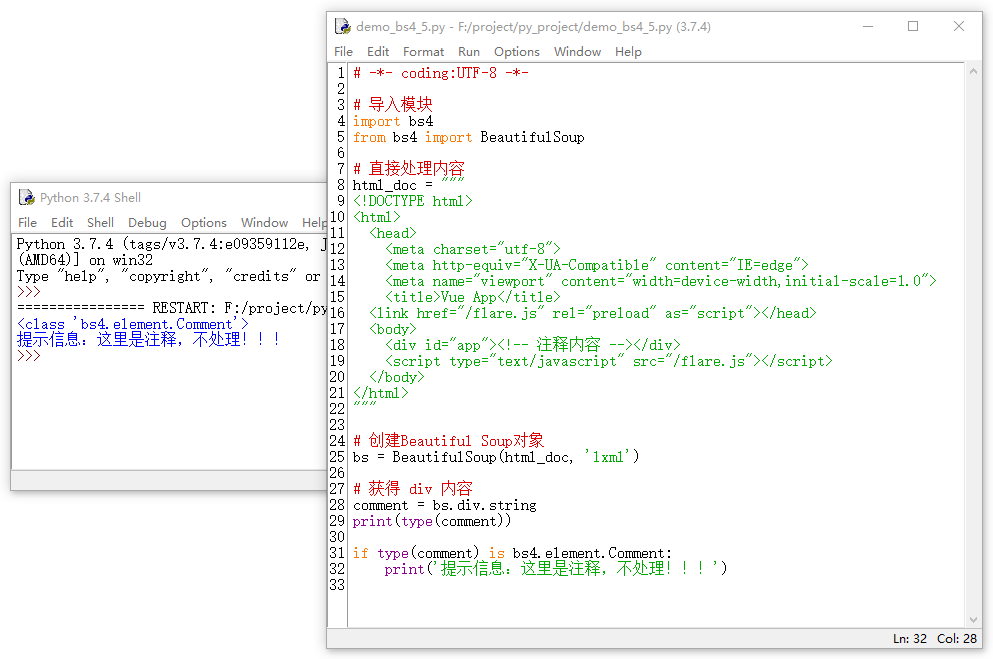
千万不要忘记导入一下模块呀。
import bs4
由于之前直接导入的是bs4中的BeautifulSoup方法,如果不导入一下bs4的话,没有办法进行条件判断。完美的写法应该是如下的。
七、文档树的遍历
7.1 子节点遍历
在子节点遍历中,有两个方法可以辅助对文档树的遍历功能,是 children 和 descendants ,但是在使用它们时还是有不同差异的。
7.1.1 children
children是通过遍历来获取子节点,实际上是以列表类型的迭代器。实际children的功能就是对文档内容按子节点的形式逐个遍历访问。接下来看一个示例:

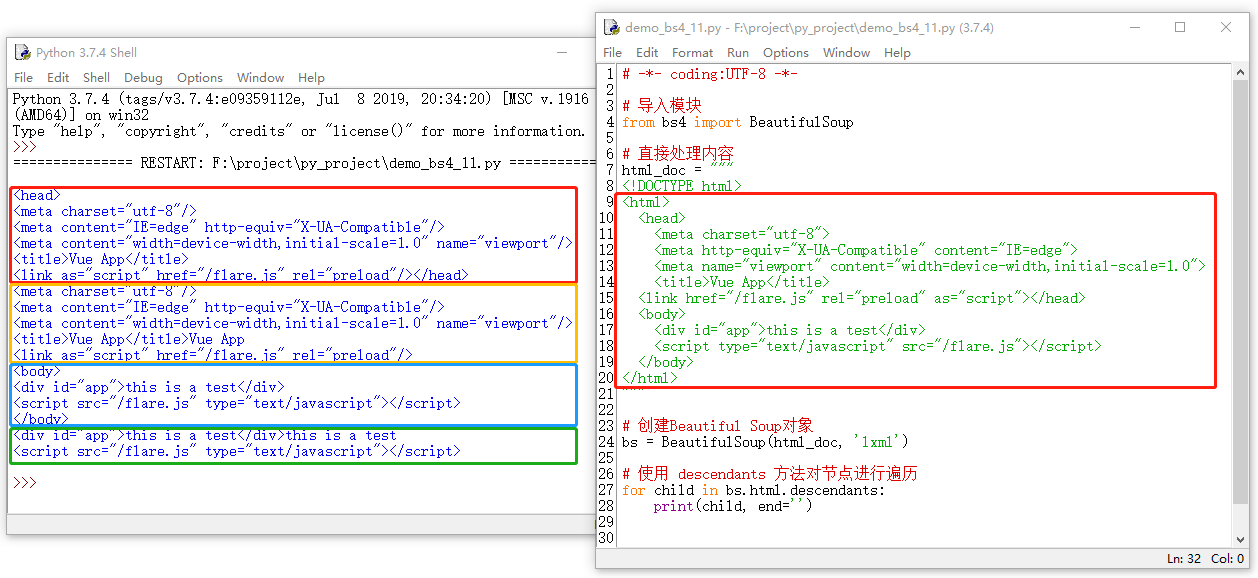
7.1.2 descendants
descendants 是通过遍历来获取子节点,得到子节点后,还会再次遍历,来获取子节点的子节点,所以这种形式,在获得子节点时,会出现重复的情况。但它也是一个迭代器。接下来看一个示例:
7.2 父节点遍历
在父节点遍历中,也有两个方法可以辅助对文档树的父节点进行获得及处理,它们是 parent 和 parents。
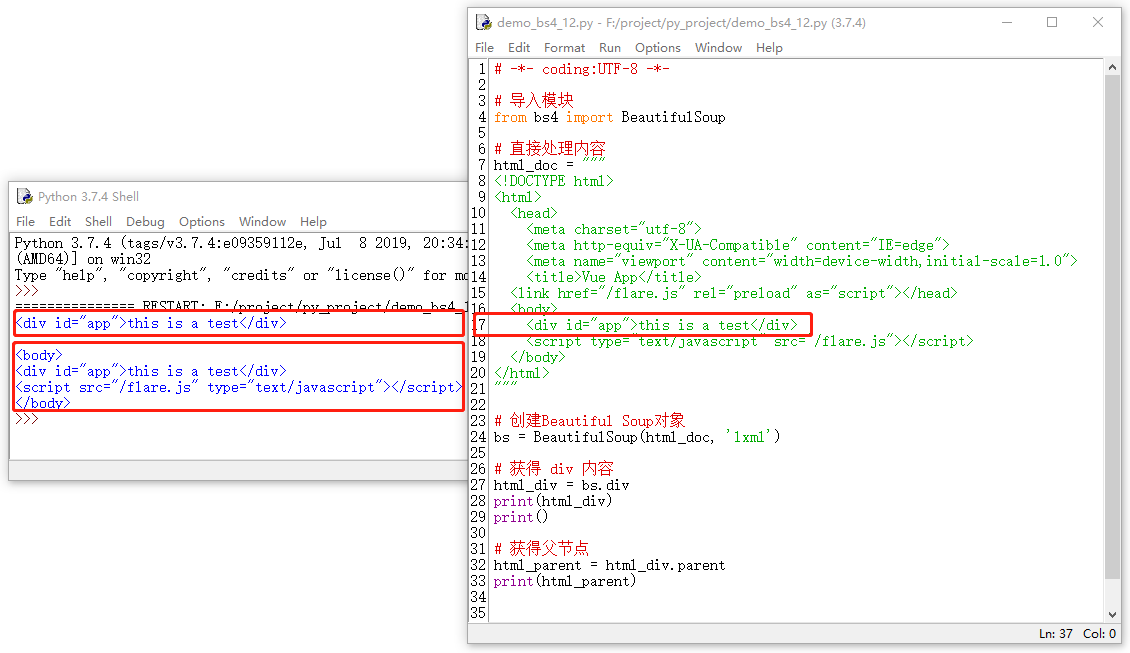
7.2.1 parent
parent是获得当前节点的父节点的功能,接下来以 div 为例来获得一下其父节点。
7.2.2 parents
根据名称parents就可以推算出它的功能,是获得当前节点的各个层级的所有父节点,同时它也是一个迭代器,接下来还是以 div 为例来获得一下其父节点。
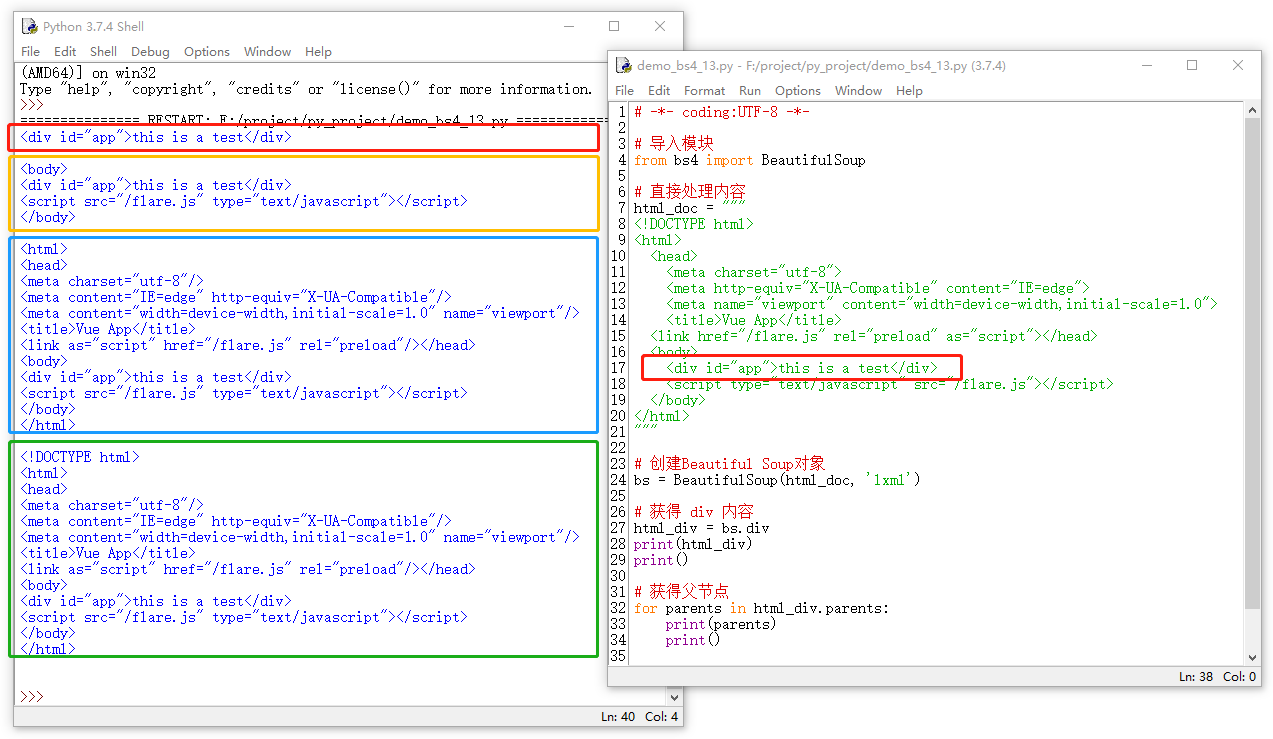
7.3 兄弟节点遍历
除了子节点、父节点之外,还有一种方法就是兄弟节点,它们是 next_sibling、next_siblings、previous_sibling、previous_siblings。
7.3.1 next_sibling
next_sibling是获得当前节点的下一个同级节点,也就是下一个兄弟标签。但它有一个问题,就是在获得下一个同级的兄弟节点时,需要执行两遍,接下来看一下示例:
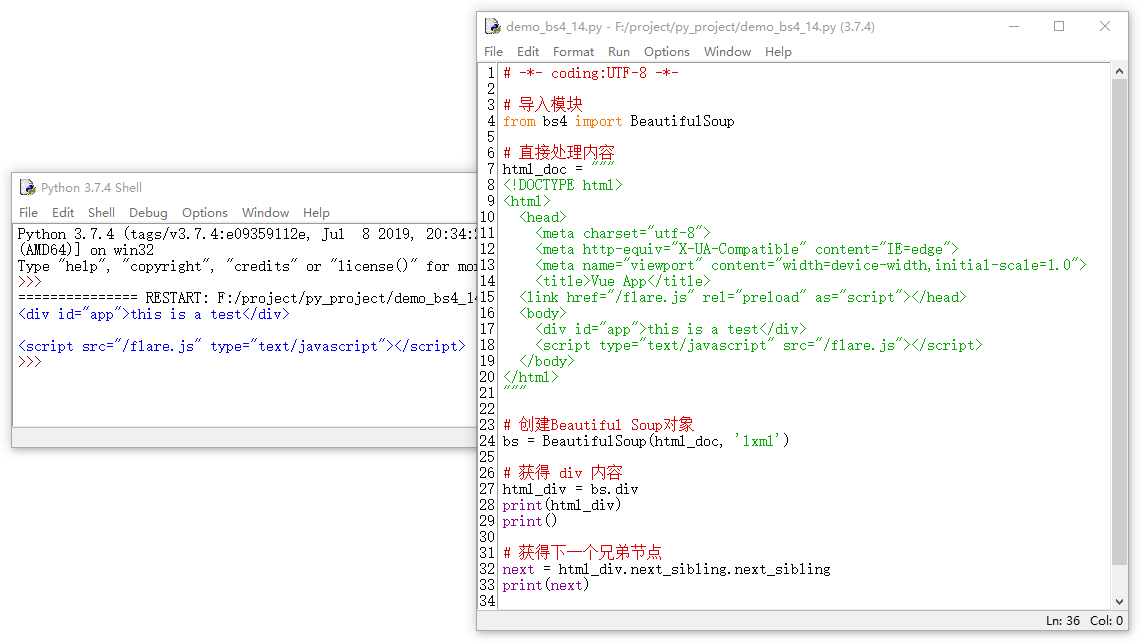
对于操作的 div 而言,正常我们理解的是,执行一下 .next_sibling 就应该获得到 script 标签的内容,但实际上是不行的,我们需要执行 .next_sibling.next_sibling 才能获得到下一个兄弟节点标签内容,具体为什么,我们会在下面的示例中说明。
7.3.2 next_siblings
next_siblings是后面同级的所有兄弟标签,接下来看一下示例:
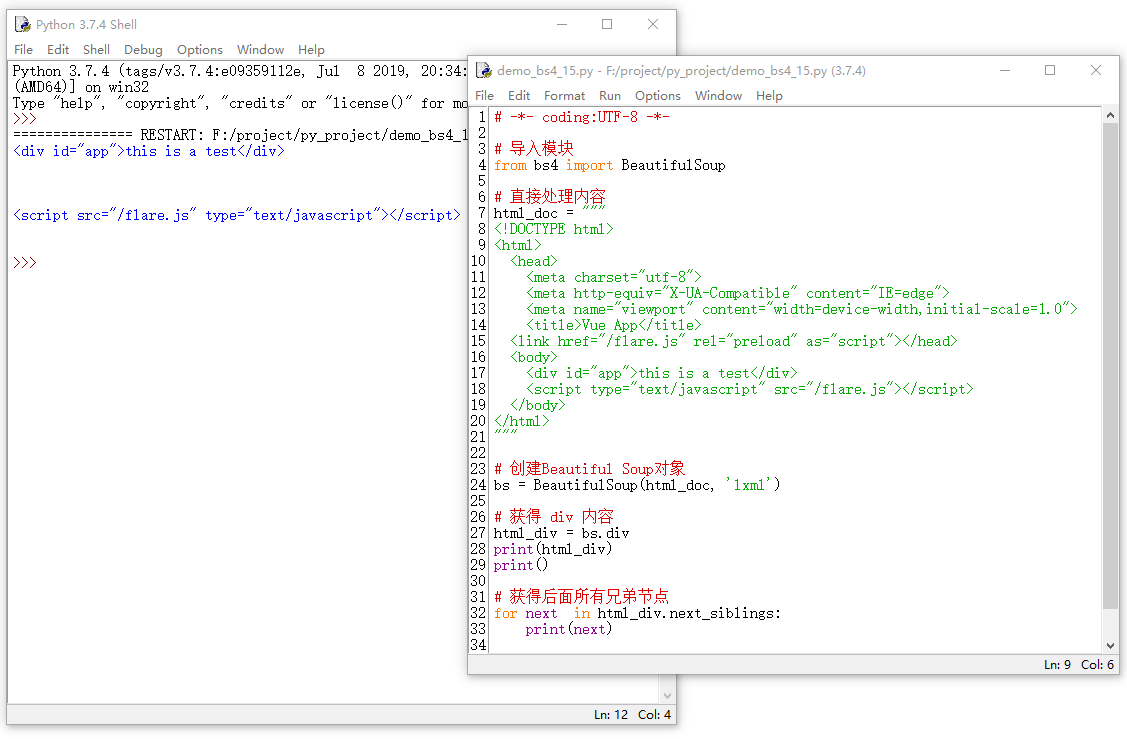
7.3.3 previous_sibling
previous_sibling、是获得当前节点的上一个同级节点,也就是上一个兄弟标签。但它有一个问题,就是在获得下一个同级的兄弟节点时,需要执行两遍和next_sibling一样,接下来看一下示例:

7.3.4 previous_siblings
previous_siblings是前面所有的兄弟标签,接下来看一下示例:

7.4 节点内容
如果一个标签里面没有其它子标签了,那么可以使用 .string 方法来获得标签里面的内容。
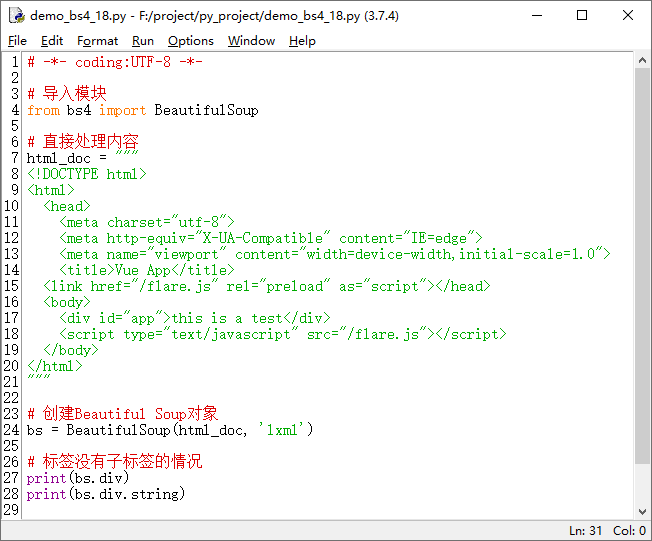
如果一个标签里面存在多个子标签,我们可以使用 .strings 方法来获得,并且要知道得到的是一个迭代器,示例如下所示:
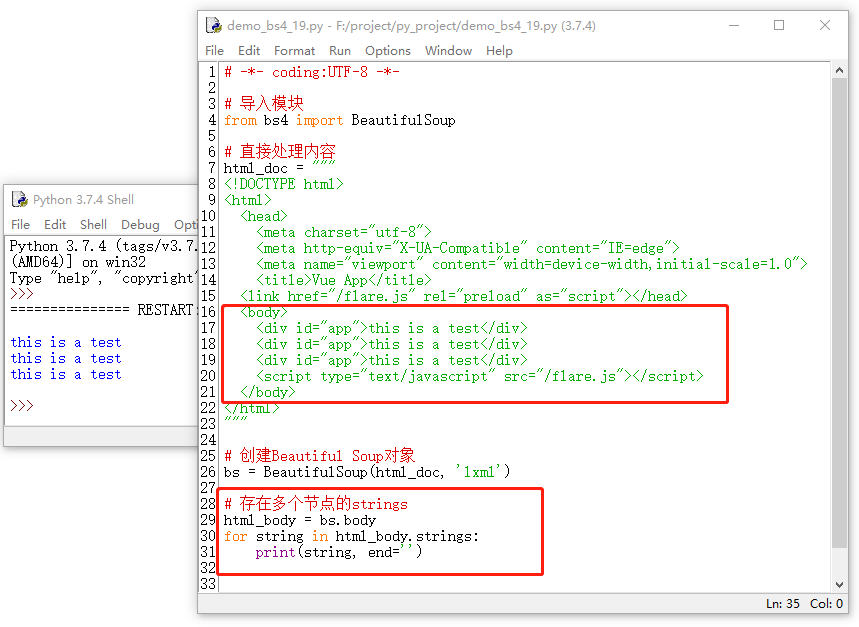
现在输出的内容,其实是经过格式化的数据,接下来我们输出一下原始数据,输出原始格式的方法是 repr() 方法,示例如下所示:

通过上面的图片可以看到,我们在原始数据格式输出时,会多出 ‘\n’ ,这也是导致next_sibling与previous_sibling为什么执行两次才行得到兄弟节点的原因了。
如果我直接输出内容,不做任何处理的话,输出时会输出很多空行,我们可以使用 stripped_strings 方法来去除空行,接下来看一组对比示例:

八、文档树的查找
在bs4中,文档权的查找有两个方法分别是 find_all() 和 find()。接下来分别对两种查找进行说明。
8.1 find_all
find_all 方法的功能是在文档树中查找符合条件的所有结果。它的使用语法如下:
find_all(name, attrs, recursive, text, **kwargs)
接下来对方法中每个参数逐一进行说明。
8.1.1 name
name为要查找内容的标签名称。返回的结果是以列表的形式展示的。

如果一下想查找多个标签名称,我们可以给name传入一个列表,将要查找的内容写在里面,就可以实现了,接下来看一下例子:
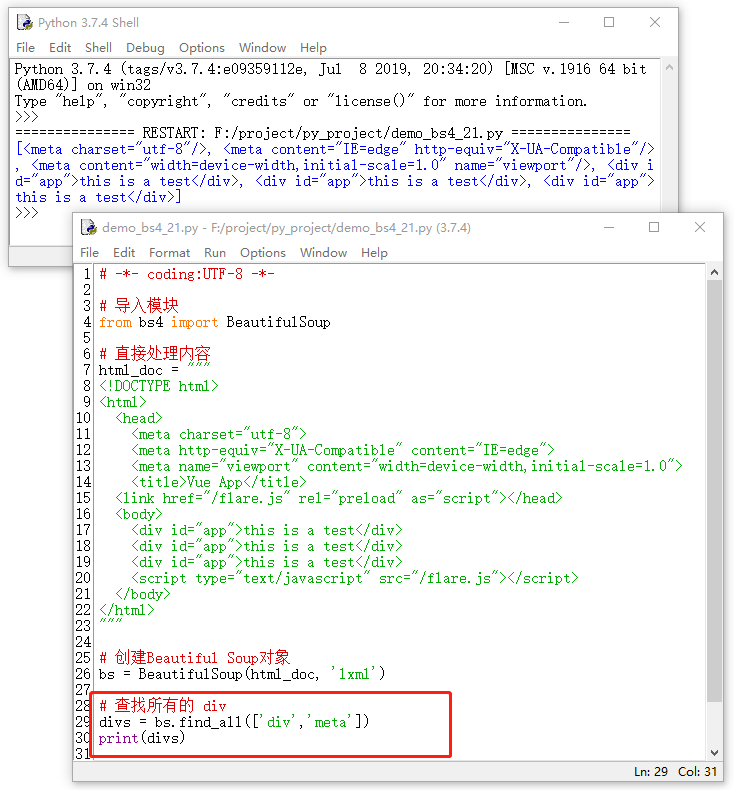
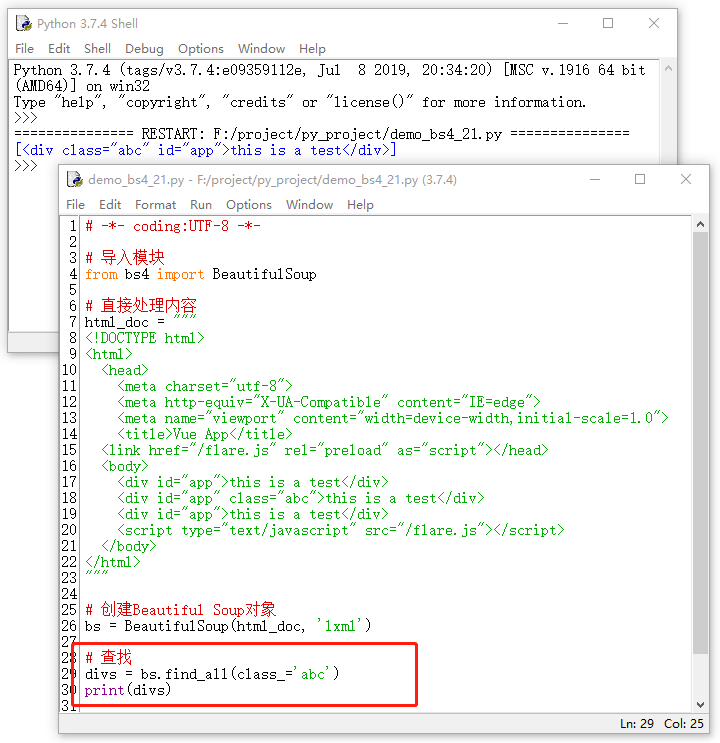
除此之外,find_all 方法可以查找任意 html 标签对的内容,如:“ charset=’utf-8′ ”、“ content=’IE=edge’ ” 等等,但是吧,有一个很特殊,就是 class=”…” 这种类型的,因为class与python中的类同名,所以需要 class_ 来代替,具体示例如下所示:
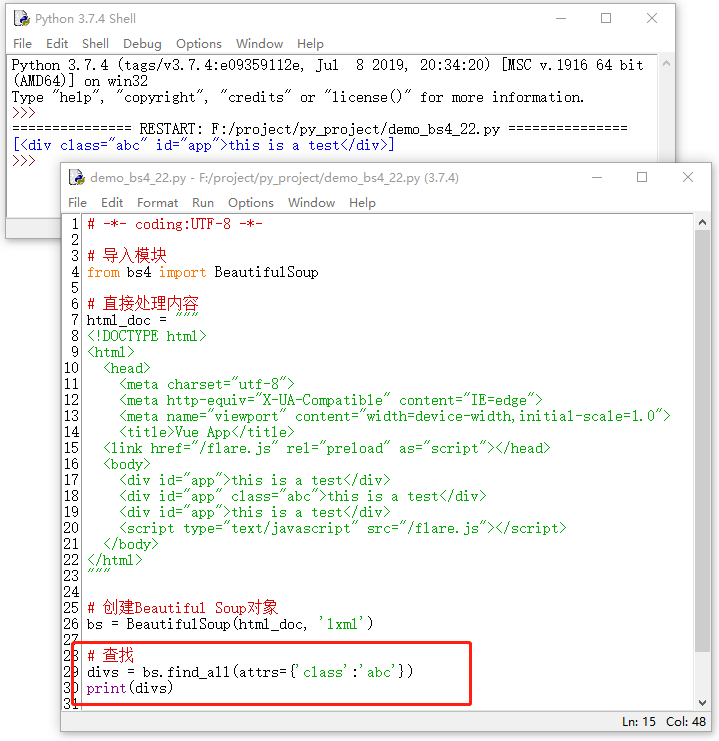
8.1.2 attrs
attrs 的出现,就是为了解决上例中查找关键字可能冲突的问题,我们可以使用它像操作字典一样来查找内容。具体示例如下所示:
8.1.3 recursive
recursive 的功能是控制是否需要递归子节点查找。如果设置为“ recursive=False ” 标志,则说明只在当前子节点下查找,查找不到返回为空列表,如下图所示:

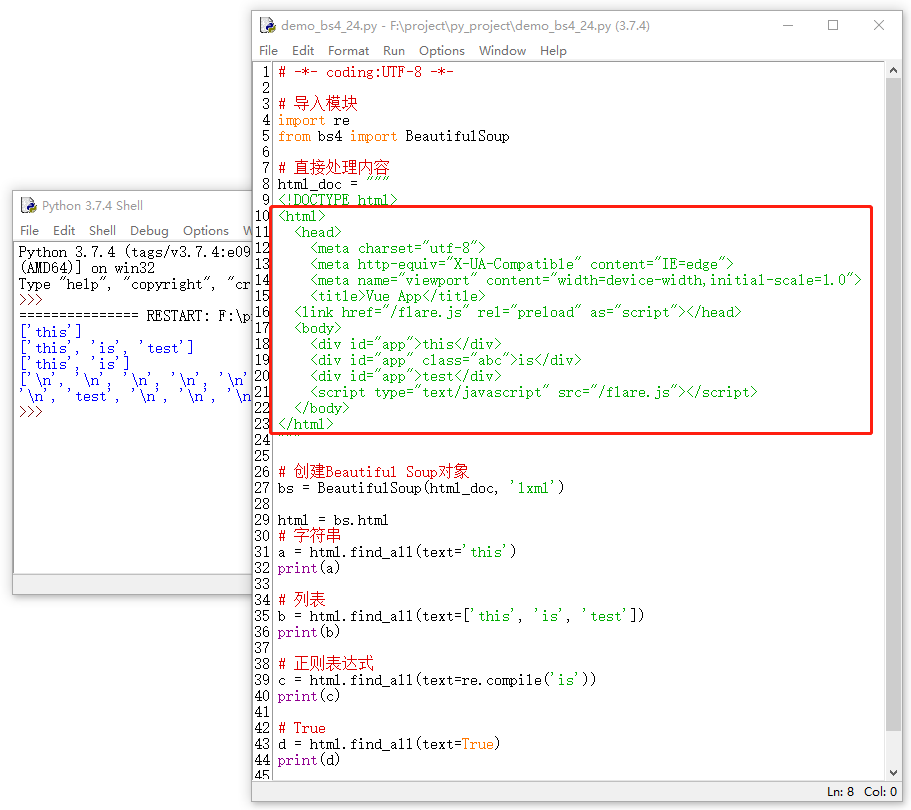
8.1.4 text
text 主要功能是来查找的文档中的字符串内容。与name参数的可选值相同:字符串、正则表达式、列表、True。同样根据下面的示例,你可以完善一下name的用法。text与name的区别是:text查找的是内容,name查找的是标签名称。
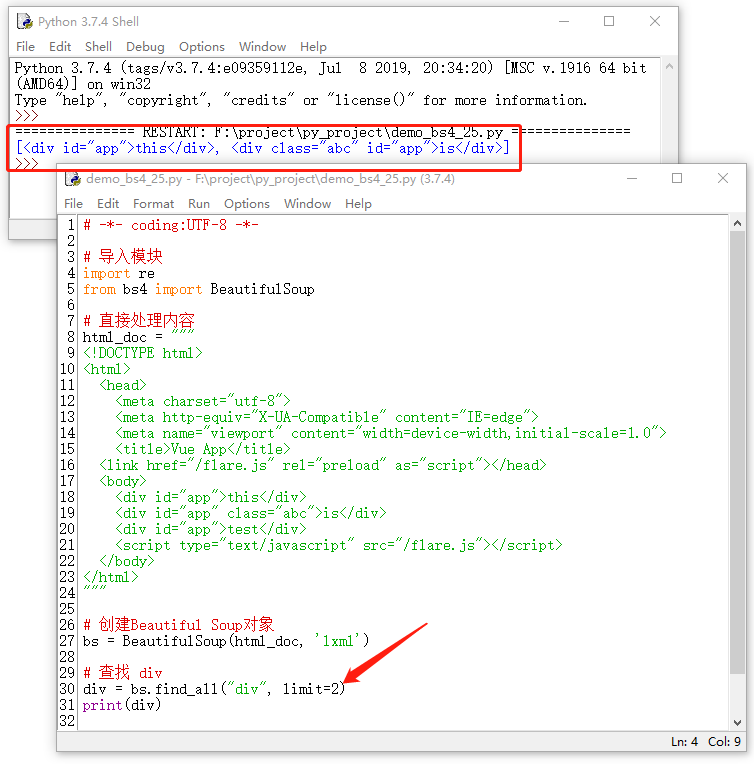
8.1.5 limit
除了上面介绍的参数之外,还有一个有用的参数,没有显示在内,它就是limit,用来限制查找内容的数量。
8.2 find
find_all 方法的功能是在文档树中查找第一个符合条件的结果。它的使用语法如下:
find(name,attrs,text,recursive,**kwargs)拉
接下来看一个查找的示例:

8.3 select选择器
bs4的select() 方法可以按标签名、类名、id名、属性名以及进行组合查找,查找到的结果都是以列表形式进行返回,接下来看一下操作示例。

在使用select()方法进行查找时,要注意,查找标签直接写名称就好,如果要查找类名,就要在类名前加个点,如果要查找id,就要在id的名称前面加#号,这个与CSS样式的标准相似。
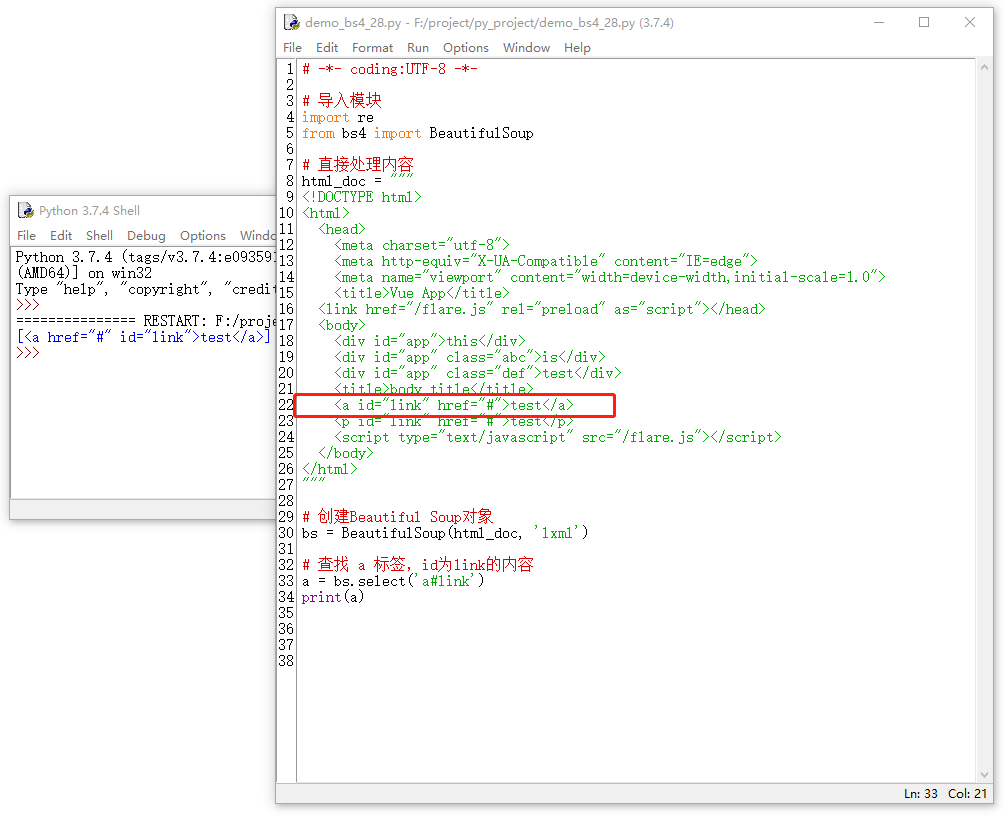
除了上面的查找之外,select()方法还支持组合查找,组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找a 标签中,id 等于 link的内容。
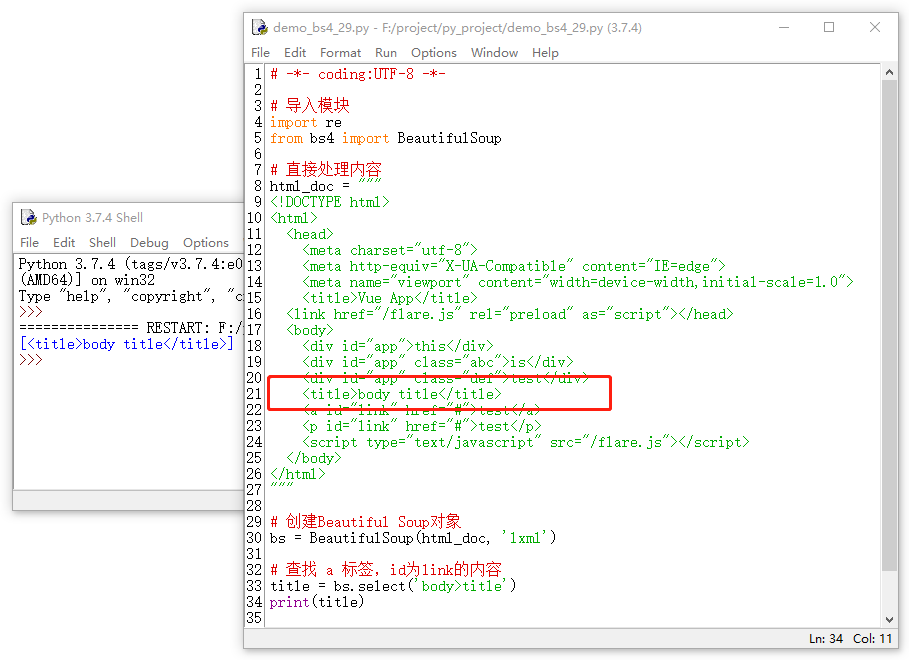
还可以直接查找子标签哟。
查找时还可以加入属性元素,即属性查找,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。

到目前为止,Beautiful Soup4已经讲解的差不多了,还想了解更多,请到官网上学习,这里不再过多描述,下课……